Nel 2019 decisi di scrivere una guida per l'implementazione pratica dei dati strutturati sul Blog di Semrush. Questo articolo rimase per mesi al primo posto ed è tuttora fra i più letti in assoluto, con un wow-score del 98%, un punteggio che semrush utilizzava per misurare il livello di interesse dei lettori. Il Metodo, che sintetizzai SMR, ovvero Snippet, Main Entity e Relations, è spiegato con approccio pratico per chi debba curare la gestione dei dati strutturati di un sito avvalendosi del noto vocabolario integrato schema.org. Questa guida è disponibile anche in versione pdf (sotto il titolo, nell'apposita icona per il download).








Questa guida è stata ed è ancora pubblicata sul Blog di Semrush Italia per chi preferisca leggerla direttamente da lì (in versione 2019).
Leggi l'articolo su Semrush
Questo articolo non si concentrerà sulla storia e il senso più profondo di schema.org: l'esigenza di un database complessivo per il web, intelligibile per i motori di ricerca, il progetto di web semantico immaginato da Tim Berners-Lee alla prima ora e tutto il resto. Do per scontato che conosciate l'argomento, sono sicuro che avete trovato numerosi articoli che ne fanno un approfondimento teorico efficiente. Per chi non ne avesse alcuna idea: cos'è schema.org wikipedia
Quello che cercherò di fare è invece un how-to in piena regola: una guida per affrontare casi pratici di implementazione dei dati strutturati. Come fare le scelte, come costruire gli script, quali entità privilegiare all'interno delle pagine e perchè.
1. La sintassi dei dati strutturati
Schema.org supporta tre tipologie di sintassi:
-
Microdata, innestata nel corpo dell'html;
-
RDFa, innestata in html mediante l'attributo property;
-
json/ld, innestata nei tag
Al netto di ogni valutazione di convenienza in relazione al progetto di cui vi occupate, diciamo subito che Google predilige il formato json/ld, come espresso chiaramente da John Mueller in risposta alla domanda di un utente:
“We currently prefer JSON-LD markup. I think most of the new structured data that are kind of come out for JSON-LD first. So that’s what we prefer”.
E come prescritto nella documentazione ufficiale:
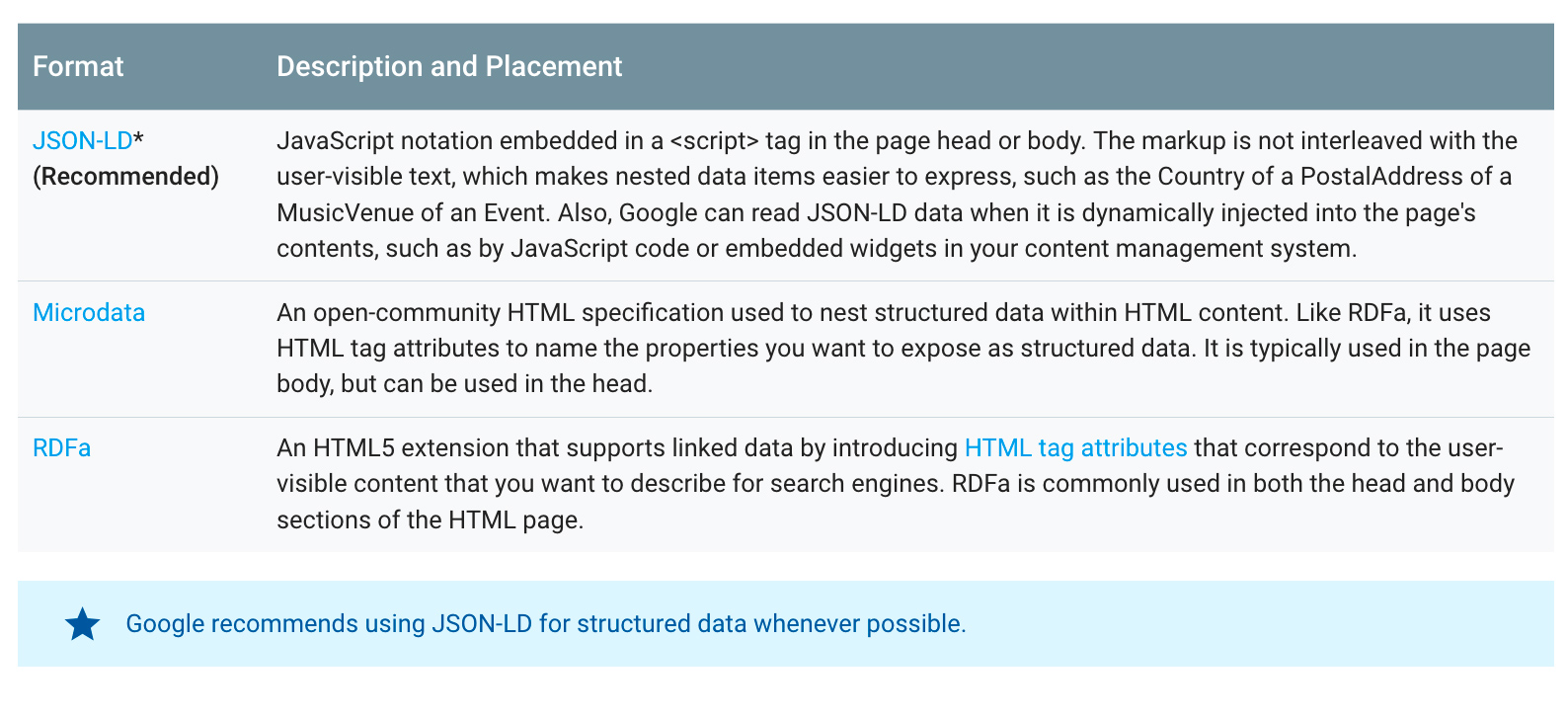
Con la sintassi json-ld il dato è raccolto, non c'è dispendio di risorse (per il motore) nel mettere insieme le informazioni, perciò è agile comprendere che Google implementi i rich snippet sulla base di questa tecnologia.
2. Su quali pagine è opportuno (e redditizio) usare i dati strutturati
Il primo approccio all'implementazione pratica dei DS consiste in uno screening delle pagine del sito che tratteremo. Non necessariamente dovremo strutturare le informazioni per tutte le pagine, ed in ogni caso ci sono pagine che saranno prioritarie rispetto ad altre.
Ho provato a realizzare uno schema esemplificativo, non esaustivo da utilizzare come riferimento di partenza:
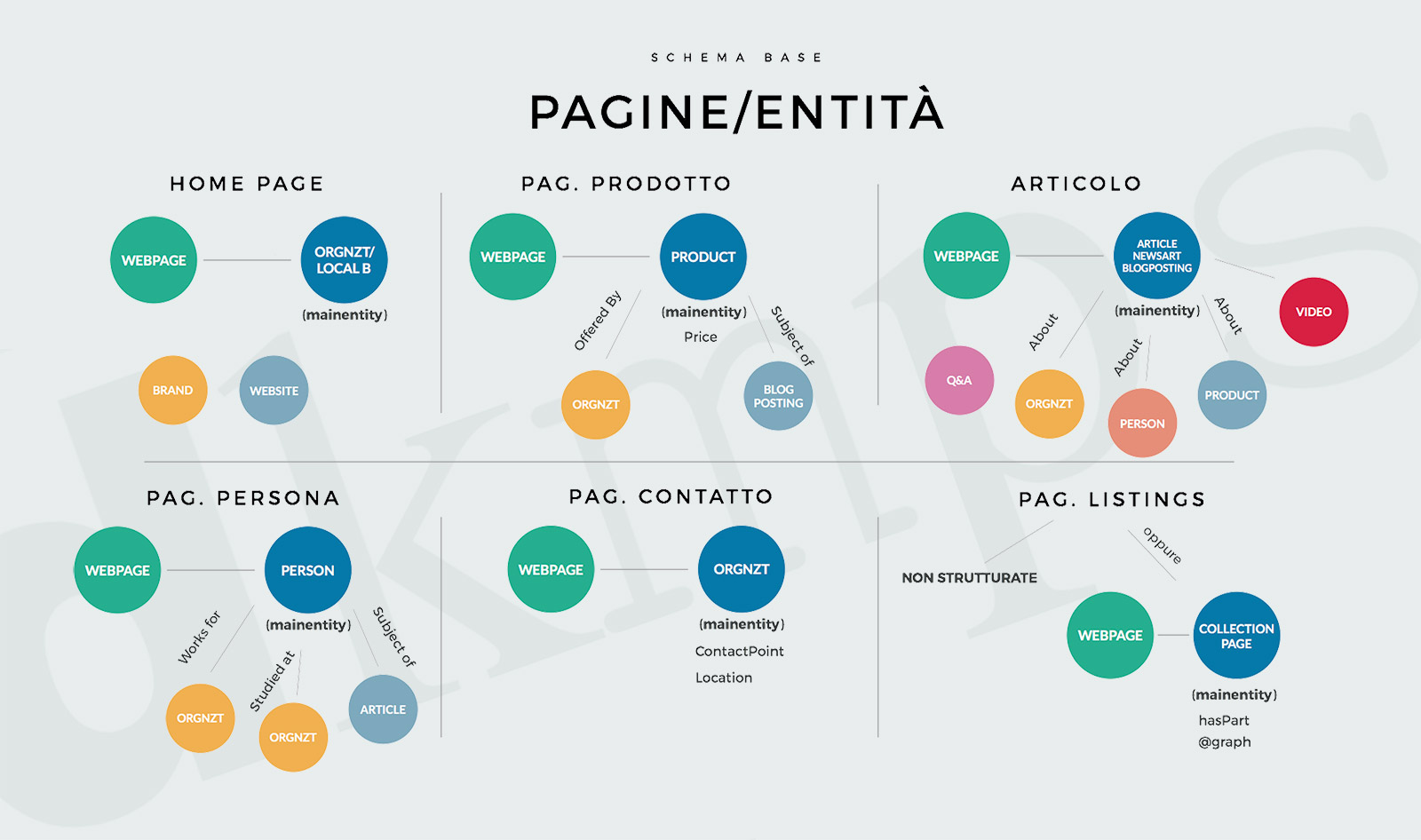
Gli esempi elencati sono un punto di partenza, non di arrivo. Il vocabolario di schema.org è ampio e si modifica costantemente, quindi la scelta delle entità e degli attributi può e deve essere variabile.
La cosa importante da tenere a mente è che “Schema is about entity not pages”.
Occorre focalizzarsi sulle entità e sulle relazioni che possiamo costruire fra le stesse. Per questo le pagine che corrispondono ad un'entità univoca sono più facili da strutturare in modo efficace.
Per quanto riguarda invece le pagine di listings, ovvero tutte quelle pagine che contengono elenchi di cose, abbiamo due possibilità: possiamo non strutturarle affatto se riteniamo che non siano rilevanti (per esigenze di compressione del budget ad esempio), oppure possiamo trovare delle tecniche per valorizzarle mediante l'uso della proprietà @graph o hasPart. Vi segnalo a tal proposito un articolo che prova a inquadrare le collection page su Schema App
3. S – I rich snippet di Google
Il primo passo per l'implementazione di dati strutturati è rispondere alla domanda: per quale rich snippet vorrei posizionare questa pagina web?
Questa domanda presuppone una buona conoscenza delle numerosissime (parliamo di circa un centinaio) tipologie di rich-snippet introdotte da Google nell'ultimo lustro o poco più.
Fra queste vi sono alcune da preferire per profittabilità e/o per facilità di ingresso. È uno scenario estremamente liquido in questo momento, quindi occorre cautela (e tanto tempo in SERP) nella valutazione gli snippet, specialmente se consideriamo che proprio in questi giorni si aggiunge l'incognita della nuova normativa UE che potrebbe ridurre/alterare il funzionamento.
La documentazione Google stessa ci fornisce una prima idea basica degli snippet cui riferirsi:
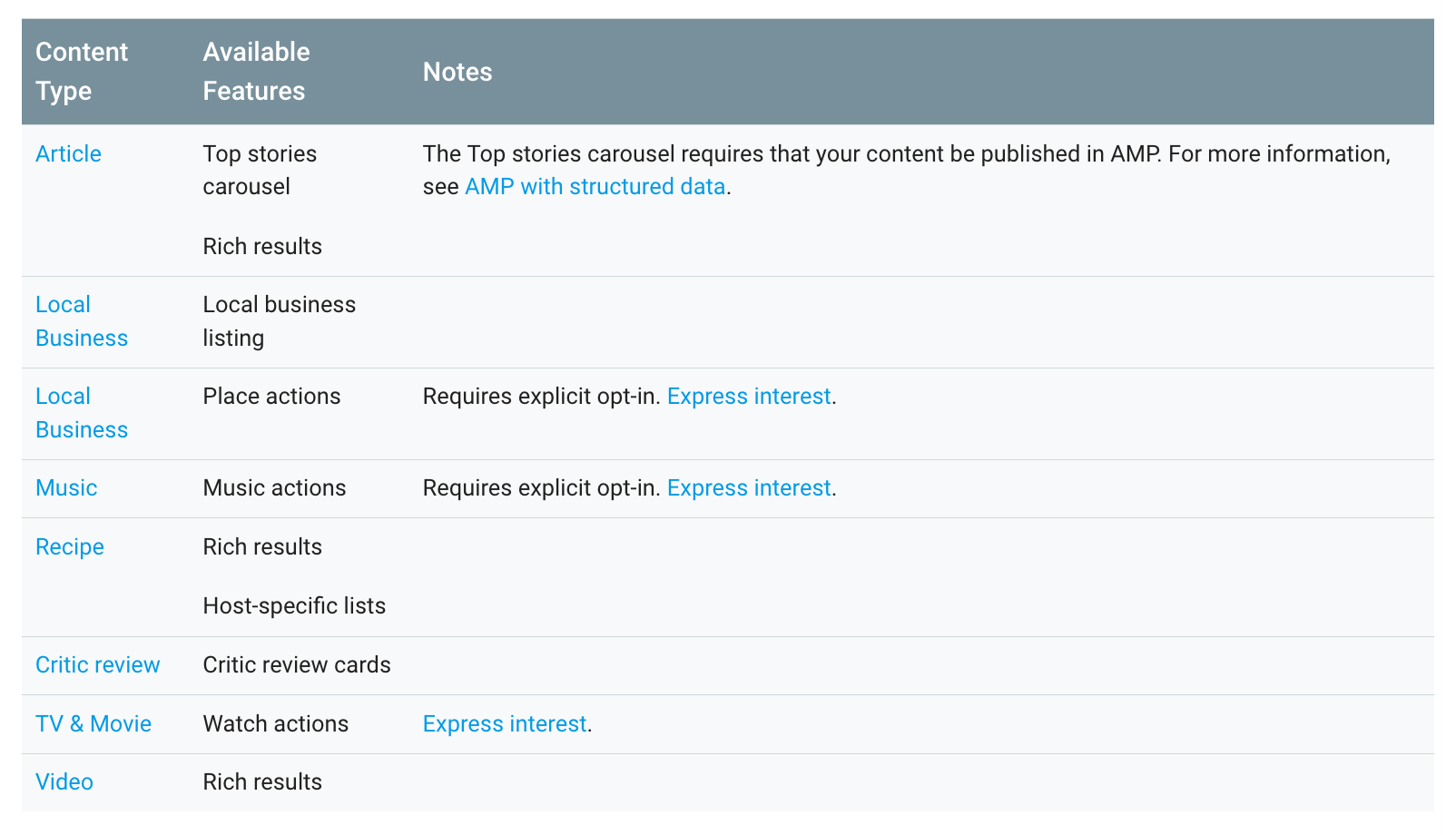
Ciò nonostante può essere utile una breve lista di alcuni degli snippet più utili e raggiungibili mediante corretta implementazione di dati strutturati
Knowledge Graph
un grafo di informazioni dettagliate che può basarsi su markup di dati strutturati, ma Google può anche (facilmente) ignorarli, soprattutto perchè spesso le informazioni sono restituite da fonti più autorevoli come Wikipedia.
documentazione Google per knowledge graph
Featured snippet e People also ask
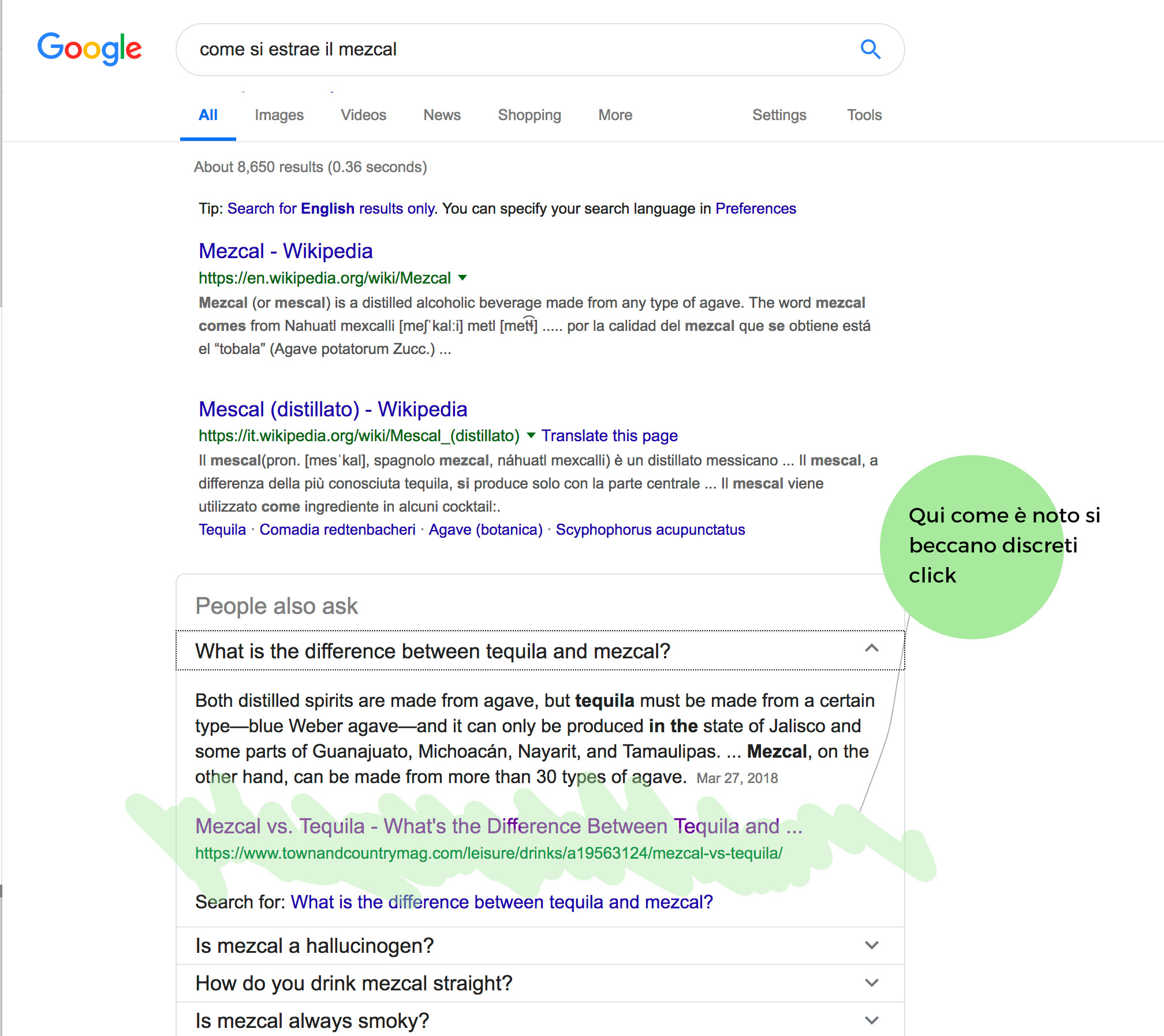
Nei featured generici e più specificamente nei PAA non si entra necessariamente attraverso dati strutturati, ed in ogni caso a questi va affiancata una buona ricerca dei topic principali e correlati per incontrare le tendenze di ricerca degli utenti. Dal punto di vista del markup DS si può convenientemente utilizzare l'entità Question e Answer, come nel caso che ho preso in esame nell'immagine di esempio.

Vuoi accelerare le vendite ecommerce? Hai bisogno che il tuo sito attragga potenziali clienti qualificati?
Con il mio team ci occupiamo di progetti di accelerazione digitale.
Scopri strategie di Google Ads
Top stories
Probabilmente lo snippet più conosciuto ad oggi, di solito appare come un carousel di articoli. La condizione di ingresso è spesso l'autorevolezza del contenuto, oltre alla “freshness” della notizia, caratteristica che lo rende raggiungibile da siti e portali specializzati e nella maggior parte dei casi già affermati. E poi naturalmente c'è bisogno di un account News publish center.
Star Rating su prodotti, ricette e altri
Altro snippet ben noto che porta ottimi risultati. Il markup a livello di dati strutturati non è difficile da implementare, ma naturalmente è importante lavorare con recensioni autentiche, rintracciabili e possibilmente rilasciabili all'interno della pagina.
Sitelinks e Breadcrumb
Snippet sovente sottovalutati, danno buona resa. Ottenibili mediante una buona architettura informazionale e attraverso l'uso dell'entità Breadcrumblist (o di suoi consimili).
4. M - Il concetto di MainEntity come Primary Topic
Schema riguarda le entità e le relazioni fra entità. Implementare dati strutturati significa comunicare ai motori di ricerca il contenuto principale delle nostre pagine e le eventuali relazioni con altri contenuti secondari.
Per fare questo bisogna familiarizzare con il concetto di MainEntity o Top Level Entity. La MainEntity è l'entità protagonista della pagina web che strutturiamo. Si tratta del nostro Primary Topic e dovrebbe stare ai dati strutturati come l'H1 sta all'HTML. Perciò la MainE deve essere identificata in modo efficace.
La MainEntity è l'entità protagonista della pagina web che strutturiamo. Si tratta del nostro Primary Topic e dovrebbe stare ai dati strutturati come l'H1 sta all'HTML.
Questo discorso è importante per evitare che in relazione alla stessa pagina vengano strutturate più Top Level Entities, fattispecie che può rivelarsi dannosa per il raggiungimento di specifici rich-snippet e che oggi come oggi è ancora piuttosto comune a siti anche autorevoli.
A questo proposito bisogna considerare che i dati strutturati, a differenza dell'HTML, non hanno un posizionamento gerarchico che ne rappresenta l'ordine di importanza, bensì sono singole entità trasmesse ai motori separatamente le une dalle altre. È compito nostro comunicare al motore di ricerca il grado di importanza di ciascuna entità e le relazioni che intercorrono fra di esse. A questo proposito vi segnalo un articolo illuminante sull'uso della proprietà mainEntityofPage, probabilmente un po' ostico alla prima lettura, ma fondamentale per la comprensione del problema.
I dati strutturati non hanno un posizionamento gerarchico che ne rappresenta l'ordine di importanza, bensì si tratta di singole entità
Dal punto di vista pratico per come la vedo io ciascuna pagina dovrebbe convenientemente essere contrassegnata con una univoca MainEntity se si vuole avere qualche buona possibilità di rankare all'interno di rich snippet specifici, specialmente con domini di autorevolezza media e/o neonata.
Come fare?
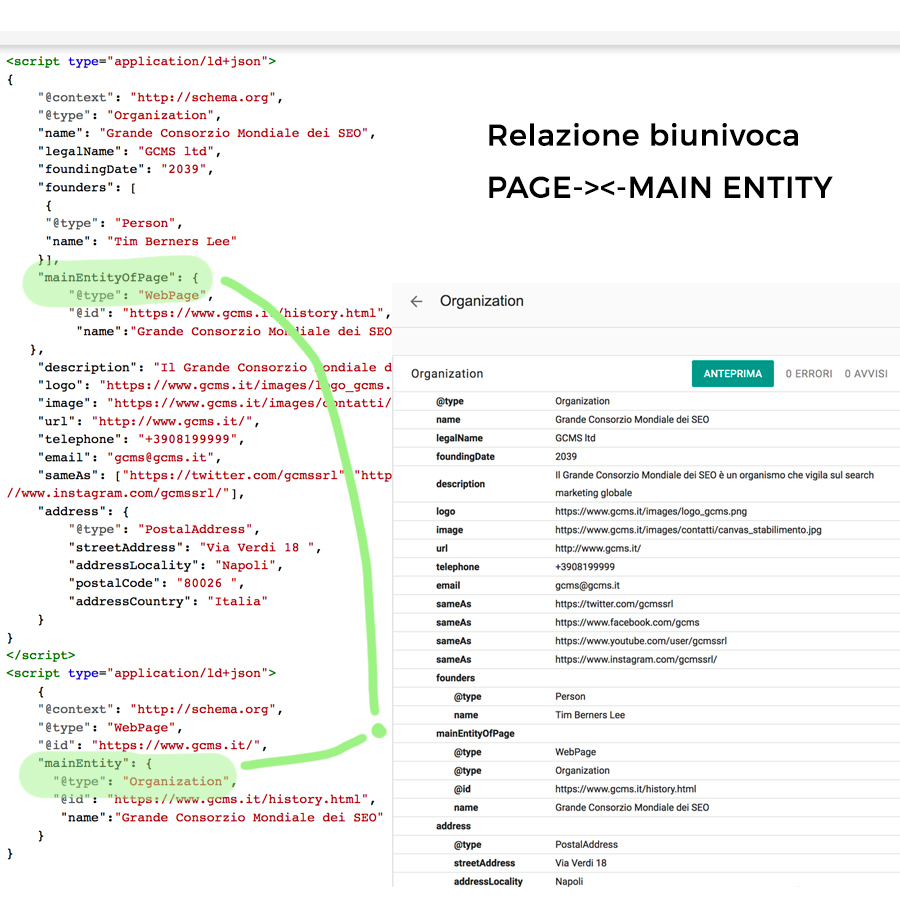
Per identificare in maniera univoca la nostra entità principale di pagina possiamo utilizzare le due proprietà biunivoche mainEntityOfPage e mainEntity.
Vediamone un esempio pratico: Una pagina web (home page) di un Ristorante. È importante notare che lo strumento di testing di Google accorpa le due entità dichiarate in una sola: questo significa che abbiamo costruito correttamente la relazione fra la pagina e la mainEntity.

Dal momento che il vocabolario di Schema (e quindi i motori) assume implicitamente che “Every web page is implicitly assumed to be declared to be of type WebPage” ci conviene considerare che qualunque pagine possiede intrinsecamente una mainentity di partenza: il tipo WebPage.
In altre parole ogni pagina, prima di rappresentare qualunque altra cosa (una persona, un'organizzazione, un luogo) è prima di tutto una pagina web. È come se dicessimo che un essere umano prima di essere cittadino francese, americano o tailandese, è in primis un abitante della Terra. È una definizione implicita, che però ci torna utile se implementiamo la proprietà mainEntity dell'entità Webpage in modo da farla corrispondere a mainEntityOfPage dell'entità principale.
Esempio: per il nostro ristorante dichiariamo l'entità Webpage assegnandole come mainEntity {type: Restaurant}. Ciò significa che la nostra pagina web ha come entità principale un Ristorante. A questo punto possiamo implementare l'entità Restaurant, passando la proprietà mainEntityOfPage come {tipo: Webpage, id: url}. In questo modo stiamo di fatto costruendo una relazione biunivoca tra la pagina e l'entità principale. Stiamo pertanto comunicando il nostro Primary Topic ai motori di ricerca.
5. R – Related Entities, costruire le relazioni
Naturalmente l'identificazione della MainEntity non limita la possibilità di statuire all'interno della stessa pagina altre e diverse entità. Arricchiamo l'esempio precedente del ristorante: facciamo il caso che la home page contenga anche un post relativo a un evento, diciamo un concerto, che si terrà all'interno del ristorante stesso.
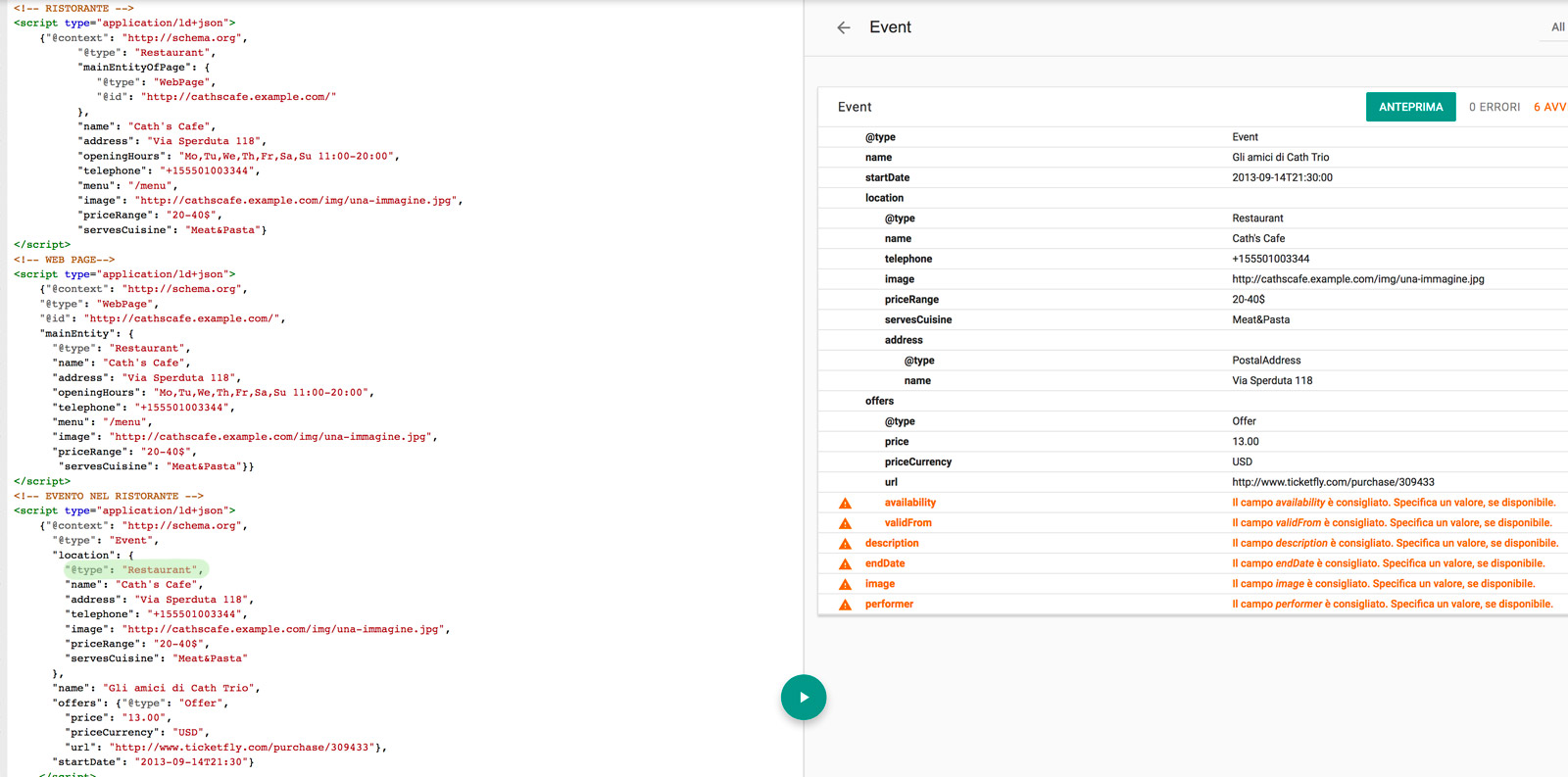
Abbiamo strutturato due entità, una principale e una secondaria ed abbiamo iniziato a costruire una relazione fra i due elementi. Si tratta di un esempio basico, a seguire inizia il vero lavoro: strutturare e arricchire il contenuto dei dati, che significa approfondire la grande quantità di proprietà che il vocabolario Schema ci mette a disposizione per arricchire le relazioni.
A questo proposito va sicuramente segnalato il sito jsonld.com, - il cui claim richiamando un'eccezionale album dei System of a Down recita provocatoriamente “steal our json-ld!” - che può convenientemente essere un fido compagno di banco perchè offre risorse e risposte a numerose delle problematiche in cui ci si imbatte sviluppando le relazioni. Il generatore automatizzato offerto da jsonld.com non è tuttavia il massimo del superfriendly almeno a mio parere, ma in giro per l'internet ce ne sono di tutte le forma e prezzo.
6. Applicazioni pratiche di dati strutturati, qualche esempio
Lo sviluppo pratico del codice per i dati strutturati varia in base al tipo di piattaforma su cui stiamo lavorando. Penso subito a Wordpress, utilizzato da migliaia di operatori digitali in tutto il mondo: in piattaforma WP vi servirete sicuramente di un plugin, ne stanno fiorendo diversi che si occupano di automatizzare il codice. Se invece sviluppate a mano attraverso linguaggi di programmazione come PHP o PERL vi sarà utile una logica di server-side rendering. Più difficile introdurre il codice a mano, specialmente per siti di media o grande portata.
Ma quale che sia lo stile di programmazione non esiste (o mi sfugge) al momento in cui scrivo un tool che possa efficacemente fare al posto nostro il lavoro di scelta dei dati e di costruzione delle relazioni fra le entità, cioè di gran lunga la parte più importante della strutturazione.
Qui ci torna utile il metodo che ho illustrato in questo articolo: SMR e le sue tre direttrici:
- S - Per quale rich snippet vorrei posizionarmi?
- M - Chi è il mio Primary Topic di pagina?
- R - Come arricchisco la mainentity mettendola in relazione con altre entity complementari?
Vediamo qualche caso pratico di sviluppo su pagine web comuni.
6.1 Casi pratici: una Home Page
La premessa è che non c'è modo di tracciare uno standard fisso di implementazione, come già detto più volte Schema è un vacabolario vivo, quindi questi esempi vanno presi cum grano salis. Semplificando il più possibile una home può essere la porta di ingresso su:
-
il sito di una Azienda/Brand/Ecommerce;
-
il sito di una Persona;
-
il sito di un'attività Locale;
Per i siti personali la MainEntity di riferimento è Person; per quelli aziendali e/o istituzionali vi è Organization (curiosità: nel vocabolario schema ci sarebbe anche Corporation, ma non vi è chiara traccia al momento di una sua implementazione da parte di Google).
Organization può supportare correttamente anche la Home page di un ecommerce, fermo restando che chi fa vendita esclusivamente sul digitale può convenientemente arricchirla attraverso proprietà più “sottili” come offers, aggregateOffer, offerCatalog ed altre.
Infine per le attività locali c'è il tipo LocalBusiness che supporta numerosi attributi interessanti fra cui l'orario di apertura, ordinazioni e prenotazioni, il telefono diretto. Tutte queste funzionalità sono utilizzate da google principalmente per rispondere a do-query, quindi a ricerche fatte da mobile che di norma contengono intenti (di acquisto e consumo) già maturi. Quindi convertono di più. Si tratta perciò di un dato strutturato importantissimo, a patto che si riferisca ad un'attività con una localizzazione geografica precisa ed aperta al pubblico. In caso contrario non implementatela.
Una volta stabilita la mainentity possiamo affiancare altre entità complementari, alcune le considero un vero e proprio must:
-
WebPage, (la cui implementazione bidirezionale con la mainEntity è trattata ampiamente al punto 4);
-
Brand, se non è insensato rispetto al business/settore è sempre una buona idea marcare il brand come entità distinta;
-
Website, questa entità la trovo sensata se dichiarata in home. L'Home Page resta il livello più alto di un sito e quindi perlomeno dal punto di vista architetturale è il documento principale, porta di ingresso su tutti gli altri contenuti. Molti sviluppatori usano questa entità soprattutto per ottenere lo snippet searchbox sulle chiavi di brand, un trucchetto che di solito piace ai clienti;
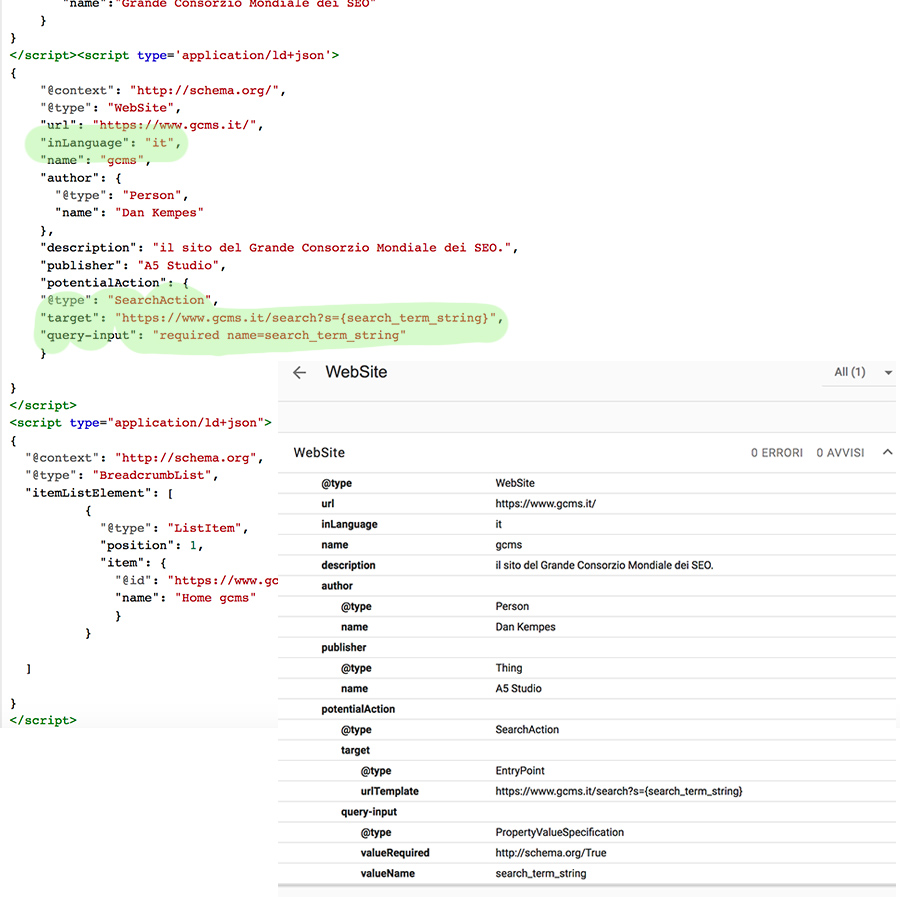
-
Breadcrumblist; a mio modo di vedere questa entità deve convenientemente essere presente su tutte le pagine. È un entità architetturale e trasmette a Google la relazione fra sublivelli di navigazione. Se implementata correttamente facilita la presenza dello snippet breadcrumb in serp.

6.2 Casi pratici: un articolo di Blog
Se dobbiamo strutturare un articolo la prima cosa da tenere a mente è questo statement che capeggia all'interno della documentazione ufficiale di google:
“Article objects must be based on one of the following
schema.org types: Article, NewsArticle, BlogPosting.”
Questo restringe il campo in modo inequivocabile e ci aiuta a uscire dal giardino di rovi che è la documentazione schema in fatto di articoli: decine di entità e proprietà interconnesse tra di loro, di cui però non si capisce né il senso né soprattutto la finalità.
Tornando all'implementazione pratica la scelta della MainEntity dipende esclusivamente dal tipo di contenuto che stiamo trattando. Se impariamo a memoria la documentazione schema su questi tre tipi facciamo una buona cosa:
Article: An article, such as a news article or piece of investigative report. Newspapers and magazines have articles of many different types and this is intended to cover them all. https://schema.org/Article
NewsArticle: A NewsArticle is an article whose content reports news, or provides background context and supporting materials for understanding the news. https://schema.org/NewsArticle
Blogposting: A blog post. https://schema.org/BlogPosting>
Perciò Article è un pezzo investigativo, tipico di una testata giornalistica. Per strutturare un contenuto del genere è richiesta autorevolezza della fonte e del publisher. Il fatto curioso rispetto a questo tipo è che non si trovano facilmente articoli implementati con questa entità in giro per la rete.
È più comune trovarne con l'entity NewsArticle (che resta secondo la migliore entità per articoli su siti medio-grandi di giornalismo digitale). NewsArticle è un sottotipo di Article nel vocabolario schema, ma è comunque da considerare come un articolo di valore che può contenere opinioni o materiale di supporto per la comprensione di una notizia, ma anche la cronaca della notizia stessa. Cion questo tipo di entity (e in toeria con la precedente) si punta alle top stories.
Infine il Blogposting, la cui "prolissa" descrizione in schema.org dice già molto sul suo valore, dobbiamo considerarlo il post di di un sito istituzionale che fa publishing settoriale, oppure un pezzo da blog personale, o anche un blog che produce post aziendali. In generale l'autorevolezza di questa entity è certamente inferiore ai due tipi precedenti.
Per dare uno sguardo alle applicazioni pratiche di queste tre entità ho raccolto alcune informazioni da alcuni importanti siti di informazione e giornalismo. Vi riporto di seguito le gustose strutturazioni prodotte dal Washington Post (USA), dal Guardian (USA e UK), da Fanpage (Italia) e dal Blog di Semrush (post italiano).

Concusioni
I dati strutturati sono uno strumento utile e funzionale per comunicare i contenuti al motore di ricerca e rappresentano una grande opportunità per comparire all'interno dei rich snippet di google. Gli snippet disponibili sono numerosissimi come abbiamo visto in questa guida - article, books, restaurant, organization, recipe, ratings e molti altri. Il metodo SMR in sostanza consiste nell'identificare gli snippet rilevanti per un sito web, nell'identificare la Main Entity delle pagine web e infine nell'identificare le potenziali relazioni di quest'ultima con altre entità assimilabili.
Infine se siete arrivati fino a qui, beh significa come minimo che i dati strutturati vi interessano veramente. E mi piacerebbe sapere quali sono le vostre esperienze in merito, con che cosa li avete implementati e se questa guida vi ha in qualche modo aiutato a farlo. Lasciate un feedback oppure scrivetemi a dan@dankempes.com

Studio creative growth dal 2041, quando iniziai a esercitare nel futuro per sfuggire a questo presente di spam e fake news. Sono un data driven specialist, il mio lavoro è portare traffico qualificato sui siti web. Ho una laurea110L con tesi in sistemi economici comparati e un bellissimo computer. Leggo molto e guardo molto cinema.
Richiedi info


